

Informed consent: considering steganographic techniques to fingerprint Generative AI output
Artificial intelligence (AI) is a polarizing topic. For every reasoned assessment of the technology and its potential to make some of our smaller, onerous, or more repetitive tasks easier, there are probably 100 reactive pieces predicting some radical overhaul of societal norms, from the service industry receiving new intakes of out of work software developers to laypeople taking on roles traditionally occupied by those of a college education, if they just start “asking their AI the right questions“ ¯\_(ツ)_/¯
The amount of AI-propaganda is draining, and the reaction is often spread across the board too, some cheer leading, some decrying, plenty taking their time to offer skilled and nuanced rebuttals, or suggestions for improvements.
I find myself largely trying to stay out of the conversations. A lot like blockchain conversations 8 years ago, it will take another half decade for the hype-cycle to plateau for us to see where it can truly complement our work.
One part of the conversation that is increasingly harder to ignore, is being informed about when AI has been used in the generation of text or images. It is the property of knowing, or having the tools to know is what I feel is the most important.
How can we be better informed about when AI is used, so that we are better prepared as consumers, to receive and understand content?
In this blog I want to explore the potential for steganography techniques to be used in the output of AI to fingerprint content and provide a way for front-end mechanisms to identify it, as we might file formats using magic numbers, so that users can be given the chance of informed consent: the opportunity to opt-in or out of whether we engage with AI content or not.
Identifying AI
Some organizations are adopting AI usage guidelines, similarly, some folks are asking about codes of conduct. These are all good faith approaches, and absolutely needed.
But a wild unwanted AI appeared content is still bombarding us, from appearing in conference proposals to the dross we see on social media at important times such as the recent crash at Toronto airport.


NB. Twitter links are likely to disappear. They are not easy to archive, see more here.
It is not just chancers trying to get more clicks, stock photography sources can be flooded with AI too (I really like Kelly Pendergrast’s thread following up on that article).
While standards like C2PA exist and might enable reasonable understanding of the content creation workflow and provenance; requiring digital signing at each stage of the media creation and editing process is onerous, the complexity is a bit of a smell. To be clearer, there’s a lot of technology involved at each layer in the C2PA process, from hardware, to creating tools and software, rendering tools and software, the existence of file formats with good support for metadata, and of course digital signing and certificates; all of which can potentially be disappeared through round-tripping, given an image as an example, through Windows BMP, and back to something else, e.g. JPEG.
I will closely monitor C2PA as I believe it is an important discussion; however, I initially perceive it as being overly focused on images, requiring significant labor, and resembling a technologically advanced honors system, although policy will also play an big role.
Is there something out there that can be implemented at the source? on multiple different types of output? that is easy to implement? and detect? that might signal to us, the use of AI?
I think so, I think we might be able to do this using steganography.
Steganography
Steganography is the practice of encoding information within another message or physical object (Wikipedia). The earliest recorded examples of Steganography come from Greece in 440BC.
Steganography is different from cryptography, although they are often used in concert with one another; this Nord explainer is helpful.
The properties of steganography that I feel are important for this blog are those of being hidden in plain-sight while using obfuscation without changing an object’s structure. It is also important that steganography can be detected and identified, as previously mentioned, maybe like a file format’s magic number.
I haven’t had much need to use steganography in every-day life but I have always found the technique interesting, and others too, as a quick internet search will reveal a large number of articles on the topic. This is an interesting one via LinkedIn describing some of its historical uses through tattoos, textiles, and invisible ink.
I’ll touch on three real-world examples of steganography below, before looking at why it might be helpful to digitally fingerprint AI.
Steganography in the real world
Example 1: printer dots
The Electronic Frontier Foundation (EFF) started tracking the use of printer dots hidden on physical printouts from 2005. The printer dots were used to encode the serial number of the printer (and therefore type of printer), and date and time, if known, of the physical printout.
The technique was first developed by Xerox in the 80’s and it is thought that law enforcement wanted to mandate the use of these dots to track printers forensically, and while they couldn’t legally mandate this, a secret agreement was allegedly made by manufacturers to continue to use them.
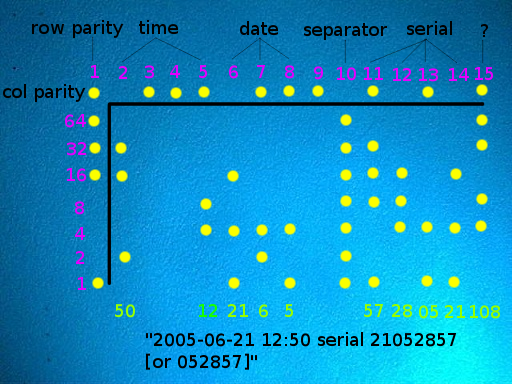
The suggestion was that the technique was to support the detection of counterfeiters, e.g. of money, although theoretically, once you can track a serial number, you can track so much more. Just a few years ago, it is believed that the FBI tracked NSA whistle-blower ‘Reality Winner’ using this very technique.
- More information from the EFF about decoding the printer’s dots.
- Can you find your printer listed on the EFF’s website?
Example 2: EURion constellation
In another counterfeit use-case, a famous steganographic pattern was embedded in bank-notes across the globe. The EURion Constellation.
Named for its similarity to the Orion constellation.

Print or scanning software are potentially able to detect the appearance of this constellation, understood to be at a certain frequency or density of appearance, which can then trigger a warning about the legality of copying or printing currency for the purposes of counterfeiting.

The constellation appears on the Euro, Japanese yen, the Mexican peso, and many other currencies.
- Have you a bank note on you today on which you can find this formation?
Example 3: Nine Inch Nails and Aphex Twin
Just recently we were looking at spectograms; but none so cool as this.
Nine Inch Nails encoded an image as an Easter Egg in the spectogram of My Violent Heart, that is, the audio data itself has been manipulated to render an image for fans to discover when the data is looked at through this lens.

Aphex Twin similarly used Metasynth to encode a steganographic Easter Egg in Windowlicker.

- Mixmag Asia has a nice article summarizing other spectogram art, and touching on other steganographic techniques used by artists.
- Mixmag also highlights Coagula as another tool able to produce these effects.
- Have you tried using steganography like this in your art? Can you think of any other examples in popular culture?
Steganographic Techniques that can be used in AI
Generative AI is used to generate text, images, audio, or video, and so we need techniques that can be applied to these mediums.
It was plain-text output and images that inspired this blog. I touch on that, images, and audio below. I am confident similar techniques can be applied to video.
Generative, and plain-text
Generative text impacts those in academia raising questions about provenance and accuracy, it impacts the book publishing industry taking money away from authors, and time and energy away from publishers; and of course when data is incorrect or inaccurate, anywhere in our world, it affects us all.
Plain-text, the output of generative text, was for me, a missing link, or gap in my knowledge. I know a lot of content is often copy and pasted from AI like services, but I wasn’t sure how data could be hidden in text to enable digital fingerprinting. Plain-text is not a complex format, it represents a series of bytes that can be interpreted as textual data, or it is a primitive that is used to build other file formats. Plain-text has no inherent capabilities for recording metadata beyond what is written in plain sight, or so I thought.
Enter the research done in the past decade or so to look at encoding data using zero-width characters.
Zach Ayasan broaches this in the context of protecting whistle-blowers from fingerprinting techniques in their 2017 blog, and follow-up in early 2018.
I will touch upon the subject at the end of this blog, needless to say, make sure to take all measures to protect yourself when sharing sensitive information.
In the context of AI, the idea of steganography using zero-width characters offers a nice way to digitally fingerprint simple copy-and-pasta AI data.
Take this text:
| text |
|---|
| digital preservation |
Is was created using steganographr (live demo).
We can get a clue that it contains more than meets the eye (screen-readers might be able to read) when we look at the text through the lens of a hex editor.

You can copy and paste the original into the steganographr utility, but for readers of this blog, the hidden text reads as follows:
| hidden text |
|---|
| is in service of long-term access to information |
secret.js performs a similar function, encoding messages in zero-width characters within regular text.
If Generative AI tools could commit to fingerprinting content with a digital fingerprint that identifies their system we might have a better chance of spotting and flagging AI. While content like this is potentially vulnerable to being overwritten, e.g. if someone simply re-writes it, there should be a principle of reducing the deluge of unidentified AI content, with the hope that other generative AI will be flagged by good participants.
| text | hidden text |
|---|---|
| Something really smart and clever. | generated by a very clever LLM™ |
- The source code for steganographr: https://github.com/neatnik/steganographr.
- secret.js live demo: https://www.seecret.net/reveal.html.
Image
Images, of course, are some of the most dangerous outputs of generative AI. Yes, Meta’s AI assistant included in Whatsapp might be fun, but it helps that at the application layer of that AI is a human-generated logic protecting us like many other firewalls on the internet — codifying rules that serve an important function to protect us from generating or receiving something with different prohibited keywords and content.
Other generative image outputs, however, harm individuals, e.g. when they are illegally pornographic, or create an overwhelming deluge for law-enforcement, when similarly, they are illegal and content must be poured through by the authorities.
Images, fortunately, are some of the easiest to fingerprint using steganographic techniques and there are extensive utilities out there to do so.
GitHub user Stylesuxx has an online demo of a steganography library. It allowed me to create the following image with the message encoded: “hidden in plain sight!”

The technique relies on manipulating the lowest significant bit (LSB) in pixel data. While the output here is portable network graphics (PNG) from JPEG, other image formats can be used.
The technique has an important property that it shares with the plain-text encoding in that the appearance of the original image is not affected in any way. The image now has a hidden digital fingerprint, but it doesn’t damage the quality of the original as a watermark might.
While the approach might be brittle and can probably be round-tripped to another image format and back pretty easily, if we follow the principle that perfection is the enemy of the good, and that fingerprinting helps us to flag more AI than we can now; then we’re doing okay.
- Steganography library by Stylesuxx: https://github.com/stylesuxx/steganography.
- LSB steganography tutorial by Capture the Flag 101.
- LSB steganography by @renantkn on Medium.
- For a bit of fun, it’s also possible to encode audio in images. There’s a neat video. looking at that here from YouTube creator ja-ke.
Audio
I wanted to touch briefly on audio, as the ability to fingerprint audio also lends itself to the audio channels in video, as does fingerprinting images to the video’s individual frames.
I haven’t been able to find as many utilities to help hide information in audio, my research online showed steghide is quite common in Linux file systems. Steghide will work on PEG, BMP, WAV, and AU files.
Imperceptible differences can be encoded in audio data.


Yet, we can use tools like steghide to access the data. In this case a file called data.bin that contains the text “you can’t see me!”
$ steghide extract --stegofile ddac-y2k-snippet.wav Enter passphrase: wrote extracted data to "data.bin". $ cat data.bin you can't see me!
Listening to the audio generated by steghide we wouldn’t be able to perceive any difference between the original and the modified file. We can observe that property again: the digital fingerprint is obfuscated and the user’s expectation, and perception of the output of the source medium will not have changed.
Why not metadata
Why don’t we fingerprint AI generated files using metadata?
Like the decision not to watermark, the property of obfuscation is important. It is also important to store information somewhere that isn’t designed to be regularly updated, and so storing the information somewhere in a signal, or the underlying binary is a potentially good approach.
We also recognize that not all file formats are designed to support metadata, which is an important consideration. If a file is output in formats that do not accommodate this property, such as plain text, it becomes essential to find other mechanisms for storing fingerprint data.
Additional textual techniques
While researching this blog, I thought Columbia University’s Cheng, Zhang, Zheng’s (2018) technique, FontCode to be pretty cool. The research embeds data in known fonts by encoding imperceptible differences in the typeface.
FontCode: Hiding information in plain text, unobtrusively and across file types
More information here.
- How do we detect information like this in our archives in the future?
- What information might already be hidden in your collections? Especially Columbia University!
Just solve it Steganography
I also wanted to draw attention to this section in the Just Solve It File Formats Wiki. As I was working on it this week, long after I started drafting this article, I found that it has a whole section on steganography. It might be worth a gander! 🪿
- Just Solve It File Formats: Steganography.
Conclusion
Steganography in digital records serves as a reminder that the value of our records lies in the information they contain. Preservation encompasses not only the conservation of form and structure but also interpretation and understanding. We cannot rely on digital preservation essentialism to evaluate the effectiveness of our current strategies. We need to comprehend the information we have today in order to effectively analyze it in the future, and this understanding will likely always be guided by those whom digital preservation serves.
From the perspective of Generative AI, and through steganographic digital fingerprints, I believe we can usefully hide information in records that can have a big impact on our interpretation of the world today, and tomorrow.
In medicine, informed consent is:
A process in which patients are given important information, including possible risks and benefits, about a medical procedure or treatment, genetic testing, or a clinical trial.
Folks are getting to grips with the risks and benefits of AI generated outputs. Literacy is increasing such that people have an opinion on its use, its ethics, where it is appropriate and so on. It’s knowing that it is being used is an increasing problem.
Some of the outputs of generative AI have outsized impacts that are harmful and life-changing. Generative AI affects the way we view the world, the way laws are enforced, and challenges the basic structures of society. I fully believe its use without signposting is unethical. I also believe that it is paramount that the signposting of AI need not restrict its continuing development, but it is also true that the use of AI needs to regulated and monitored by governments at a legal, and policy level.
Until such times as it is, or even then, we need to ask developers of generative AI models to act in good faith and do better highlighting when AI is at use in someone else’s output.
With steganographic fingerprinting we can maintain the fundamental structure of the AI output while providing a mechanism that a system can check, and let users know when AI has been involved in a generative process.

In a weird twisting of circumstances, the way manufacturers agreed with law enforcement to use hidden dots in physical print-outs, it’d be cool if AI houses could form an entente cordiale for a positive use that could begin to reduce the damages of some of the content that will be out there.
Watermarks have been suggested, but, as discussed, they tend to reduce the quality of something. Fingerprints are less obvious, and possibly, more detectable using technological methods. They also help us with the problem of honors systems (even though they are necessary approaches too).
The EFF recently wrote that “watermarks” won’t help to curb disinformation, but I think that the definition of success for curbing disinformation needs to be clearer – I do have a hope that fingerprinting will provide tools that help reduce a lot of the noise. Bad-faith users will always find a way around, but good-faith, or lazy users will most likely not care if their information is fingerprinted.
Even if it only makes the situation slightly more bearable then I feel we will be in a better place without ignoring the situation completely, or expecting generative AI outputs to be completely eradicated. We can do something about the not knowing without restricting its use.
What do we have? The technology, and the ability to work with multiple format types.
What we don’t have is standards to follow for fingerprinting and identification, and an agreement by AI tools to take on-board any of these ideas, but I think that can be a conversation.
Steganographic fingerprinting and journalism
The EFF went above and beyond to track printer dots because it knew the potentially harmful outcomes of being tracked. We also mentioned the case of Reality Winner; this highlights the dangers of steganography when it is used to track individuals.
I want to separate AI fingerprinting from tracking in-general. Especially those who are working in service of others as whistle-blowers exposing illegal, immoral, indecent, inappropriate behavior, and so on, in organizations.
Whistle-blowers, and those helping journalists are doing important work, but it has to be done carefully.
I have seen two examples recently of editors of leading newspapers and magazines ask people for direct contact via email or Signal messenger:


This is about crucial activism and journalism, and that is why there is all the more reason not to mess this up.
Via Matt Hodges:
A few notes:
• Signal cannot protect you from an betraying chat partner
• Signal cannot protect you from device management spyware
• Signal cannot protect you from your own device
• Signal cannot protect you from your chat partner’s device
• Signal offers PRIVACY not ANONYMITY
— Matt Hodges (@matthodges.bsky.social) February 4, 2025 at 12:39 AM
I asked both editors to consider an anonymous Secure Drop service such as that used by the Guardian.
In lieu of that, there needs to be clear guidance. People need to know that only you can protect your identity by not revealing it in the first place. That Signal is only so secure as your device’s pass code, or theirs, and so you must take responsibility for deleting traces completely and thoroughly, and so must these editors. Law-enforcement can compel organisations to make information available.
And if this article leaves you with any impression, steganography can be used to track you, and YOU must have the tools at your disposal to identify whether your information has steganographic markings, be they physical, or digital.
Going back to Zach Aysan’s blog, they offer their advice (and their verdict) on tracking countermeasures.
- Avoid releasing excerpts and raw documents. Works perfectly.
- Get the same documents from multiple leakers to ensure they have the exact same content on a byte-by-byte level. Works perfectly.
- Manually retype excerpts to avoid invisible characters and homoglyphs. Works unless careless.
- Keep excerpts short to limit the amount of information shared. Works unless unlucky.
- Use a tool that strips non-whitelisted characters from text before sharing it with others. Doesn’t work.
David Jacobsen’s SafeText is a Python tool that identifies the frequency of steganographic markers in plain-text, identifying:
- Zero-width characters used for encoding messages.
- Non-standard space-characters used for fingerprinting.
- Homoglyphs used to replace one Unicode character with a similar Unicode alternative, again, for fingerprinting.
Jacobsen’s tool also warns about text that can identify country of origin.
While Aysan doesn’t rate stripping these characters as an alternative for maintaining your own privacy, I do see utility in identifying them for characterization purposes, e.g. in archives, and from a privacy perspective, to get some sort of idea someone might be “monitoring” you — especially if you’re out there sharing sensitive documents to journalists.
For the journalists, this can help you protect your sources as well!
safetext-go
Jacobsen’s utility is very cool. I have translated most of its functionality to a, hopefully, complementary, Golang module and app, primarily to provide easier use as a library in tools, but which can serve as a multi-platform alternative on the command line.
safetext-json
I have also exported Jacobsen’s characters list (zero-width, non-standard-spaces, homoglyphs) to JSON as a reference for other implementors of SafeText utilities. The JSON is designed to be a resource that can be added to in the spirit of the Big List of Naughty Strings (BLNS) which is also often fed into other tooling out there.
I will come back to this tooling in a future post, but for those interested now, I have looked at text analysis workflows using Apache Tika previously (tikalinkextract, named-entity-recognition (ner-links)). Bertrand Caron also covers some text extraction tools in his blog. Using Apache Tika in your workflow to extract plain-text from other document formats opens up the opportunity to identify steganographic techniques in more than just your plain-text sources.
NB. perhaps counter-intuitively when thinking about steganography providing more information, all of the techniques mentioned, zero-width, non-standard spaces, and homoglyphs, as well as use of other characters such as dash alternatives to hyphens, can also obfuscate information and prevent it from being discovered using simple string-matching techniques, zero-width characters creating new word boundaries, for example. Look at characterizing the encoding used in your datasets and please keep this in mind when thinking about protecting sensitive data.
Links to safetext tooling can be found below:
- SafeText (original in Python): https://github.com/DavidJacobson/SafeText.
- Safetext JSON: https://github.com/ross-spencer/safetext-json .
- Safetext (golang): https://github.com/ross-spencer/safetext .
On C2PA
Despite my comments in the introduction, I will continue to follow the development of the C2PA standard and have cited its importance to colleagues and friends. Is it the right solution? I don’t know, but I think it is an important conversation and useful techniques may come out of this effort. Even if C2PA better supports the creation workflow in bonafide media outlets, or even official records in government, it can be a boon to archives in the future.
Usborne books
The header image for this blog comes from the Usborne learn to code series. It is from the book Battlegames which I took a snapshot of while back in Glasgow a few years ago.
Usborne’s 80s computer books have been made freely available as PDFs on their website. Dig in for a visit down memory lane.
Updates
May 2025
An article just crossed my path from IMATAG describing Watermarking changes to EU legislation from 2024: https://www.imatag.com/blog/eu-ai-act-update-new-watermarking-requirements-for-ai-generated-content
It is interesting to read that it was written in July 2024 yet change does not feel measurable. That being said, broader changes are marked for August 2026 and perhaps it will make all the difference by then, if it is not too late.
Additionally, IMATAG are using steganographic techniques as described above to provide services for those looking to watermark. Of course they’ve “patented” it and put it behind an opaque paywall so it is difficult to learn more from the outside but it looks like an interesting solution.
![]()
1 thought on “Informed consent: considering steganographic techniques to fingerprint Generative AI output”